はじめに
Python の浅いコピーと深いコピーについて勉強したのでまとめようと思います。
浅いコピー・深いコピーの定義
Pythonの公式ドキュメント では、浅いコピーと深いコピーを下記のように定義しています。
浅い (shallow) コピーと深い (deep) コピーの違いが関係するのは、複合オブジェクト (リストやクラスインスタンス のような他のオブジェクトを含むオブジェクト) だけです:shallow copy ) は新たな複合オブジェクトを作成し、その後 (可能な限り) 元のオブジェクト中に見つかったオブジェクトに対する 参照 を挿入します。deep copy ) は新たな複合オブジェクトを作成し、その後元のオブジェクト中に見つかったオブジェクトの コピー を挿入します。
本記事では、この定義の意味をかみ砕いて説明しようと思います。
複合オブジェクト
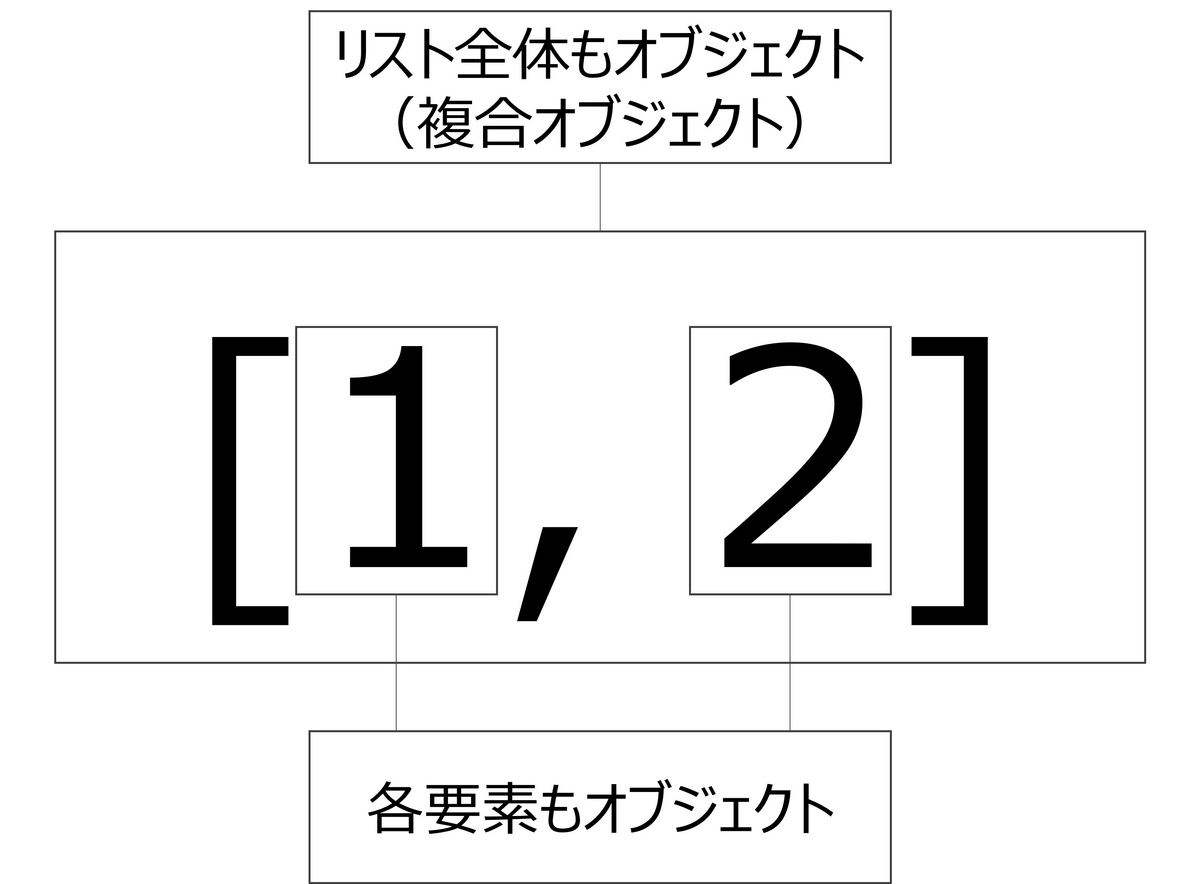
浅いコピーと深いコピーの定義に「浅い (shallow) コピーと深い (deep) コピーの違いが関係するのは、複合オブジェクト (リストやクラスインスタンス のような他のオブジェクトを含むオブジェクト) だけです」と記載があります。本節では、複合オブジェクト の意味を説明します。Python では、Python が扱うデータやプログラムコードは全てオブジェクトと呼ばれます。また、オブジェクトを複数集めて構成されるオブジェクトは複合オブジェクトと呼ばれます。[1, 2]などで定義されるオブジェクトですが、その要素1, 2もそれぞれオブジェクトです(図1)。したがって、オブジェクト[1, 2]はオブジェクト1とオブジェクト2を集めて構成される複合オブジェクトということができます。
図1:複合オブジェクトの例
オブジェクトの作成
浅いコピーと深いコピーの定義に両方とも「新たな複合オブジェクトを作成し」との記述があります。本節では、この記述の意味について、コードを通して説明します。
import copy
l = [[0 , 1 ], [2 , 3 ]]
l_copy = l
l_shallowcopy = l.copy()
l_deepcopy = copy.deepcopy(l)
print (f"id(l) ={id(l)}" )
print (f"id(l_copy) ={id(l_copy)}" )
print (f"id(l_shallowcopy)={id(l_shallowcopy)}" )
print (f"id(l_deepcopy) ={id(l_deepcopy)}" )
出力結果は下表のようになりました。
変数名
オブジェクトID
l
140418773848128
l_copy
140418773848128
l_shallowcopy
140418773850368
l_deepcopy
140418773848704
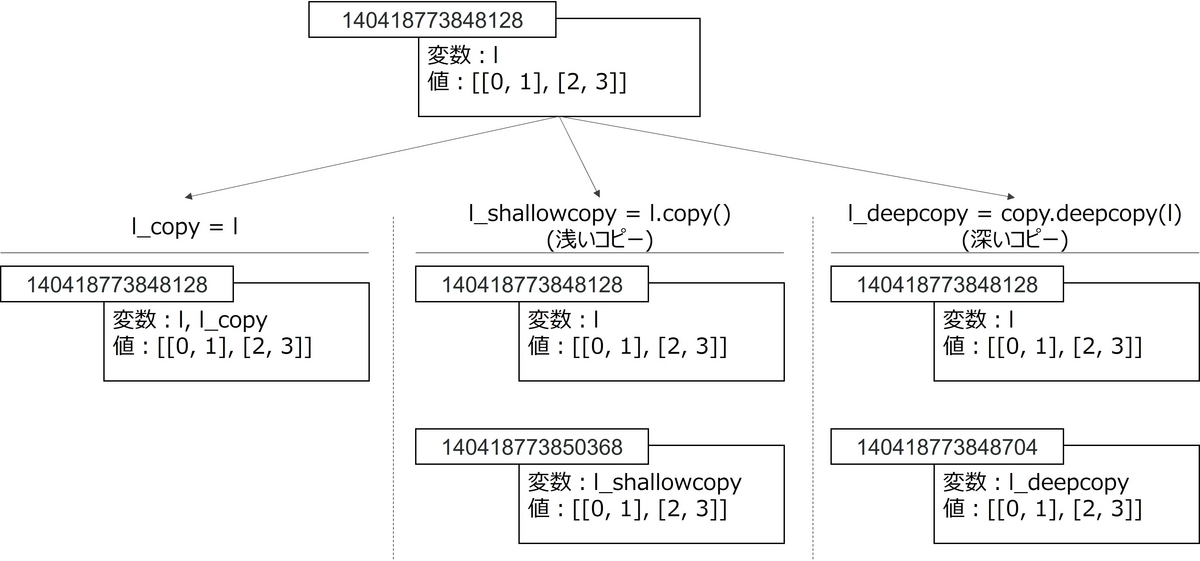
オブジェクトIDとは、Python の全てのオブジェクトに振られている固有の番号です。したがって、次のことがいえます。
l_copyとlはオブジェクトIDが同じ→l_copyとlは同じオブジェクトl_shallowcopyとlはオブジェクトIDが異なる→l_shallowcopyとlは異なるオブジェクトl_deepcopyとlはオブジェクトIDが異なる→l_deepcopyとlは異なるオブジェクト
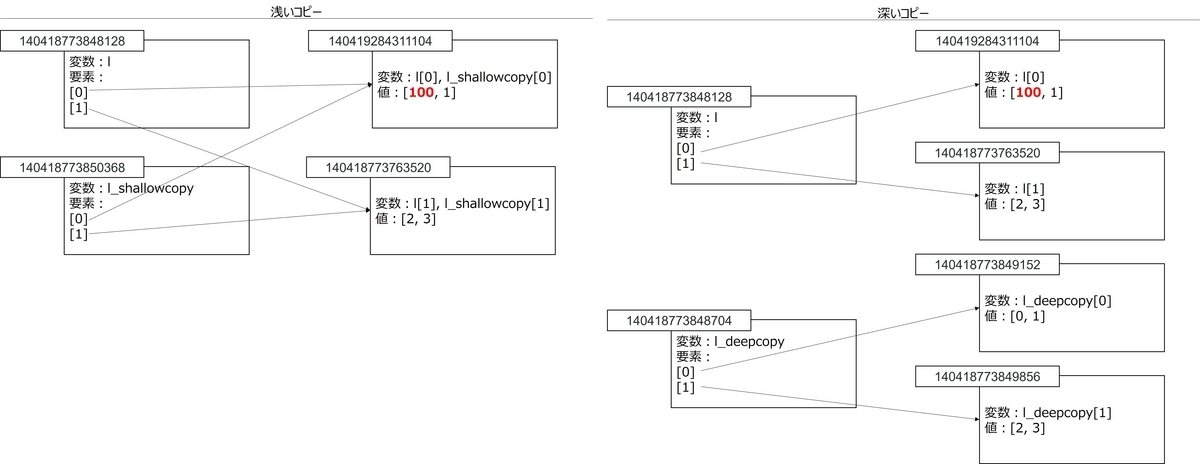
以上より、l_copy = lでは新しいオブジェクトを作成しませんが、浅いコピー・深いコピーでは新しいオブジェクトを作成していることがわかります。図2はこれをまとめた図です。
図2:コピー時のオブジェクトの挙動
元のオブジェクト中に見つかったオブジェクトに対する参照
浅いコピーの定義には、「元のオブジェクト中に見つかったオブジェクトに対する 参照 を挿入します」と書かれています。これについて説明します。
for i in range (0 , len (l)):
print (f"id(l[{i}]) = {id(l[i])}, id(l_shallowcopy[{i}]) = {id(l_shallowcopy[i])}" )
出力結果は下記のようになりました。
変数名
オブジェクトID
l [0]
140419284311104
l_shallowcopy[0]
140419284311104
l [1]
140418773763520
l_shallowcopy[1]
140418773763520
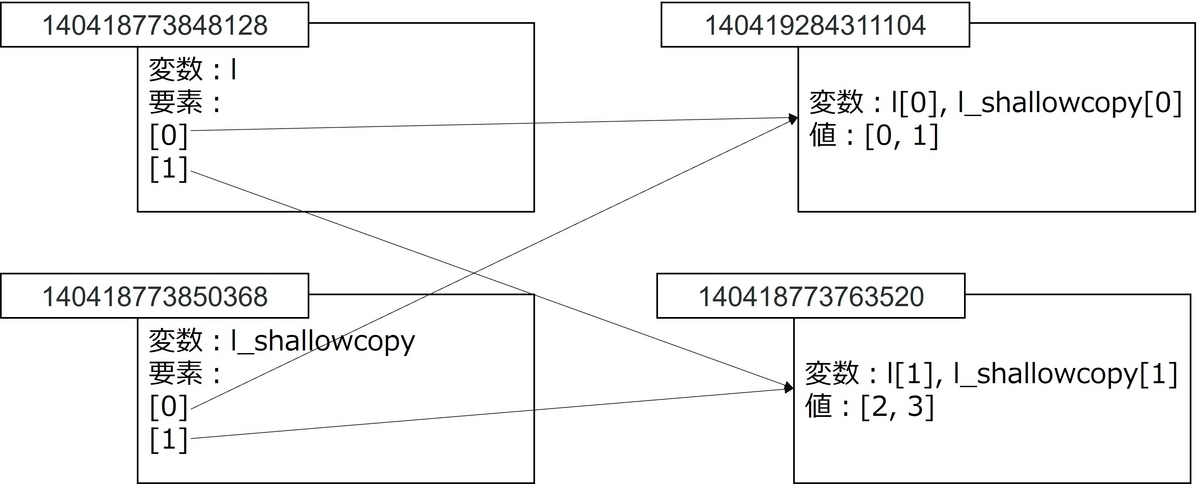
上表を見ると、l[0]とl_shallowcopy[0]のオブジェクトが、l[1]とl_shallowcopy[1]のオブジェクトが一致していることがわかります。つまり、浅いコピーを行うと、新規の複合オブジェクトが作成されるが、その要素については新しいオブジェクトが作成されません。
図3:浅いコピーで作成したオブジェクト
元のオブジェクト中に見つかったオブジェクトのコピーを挿入
深いコピーの定義には、「元のオブジェクト中に見つかったオブジェクトのコピーを挿入」と書かれています。これについて説明します。
for i in range (0 , len (l)):
print (f"id(l[{i}]) = {id(l[i])}, id(l_deepcopy[{i}]) = {id(l_deepcopy[i])}" )
出力結果は下記のようになりました。
変数名
オブジェクトID
l [0]
140419284311104
l_deepcopy[0]
140418773849152
l [1]
140418773763520
l_deepcopy[1]
140418773849856
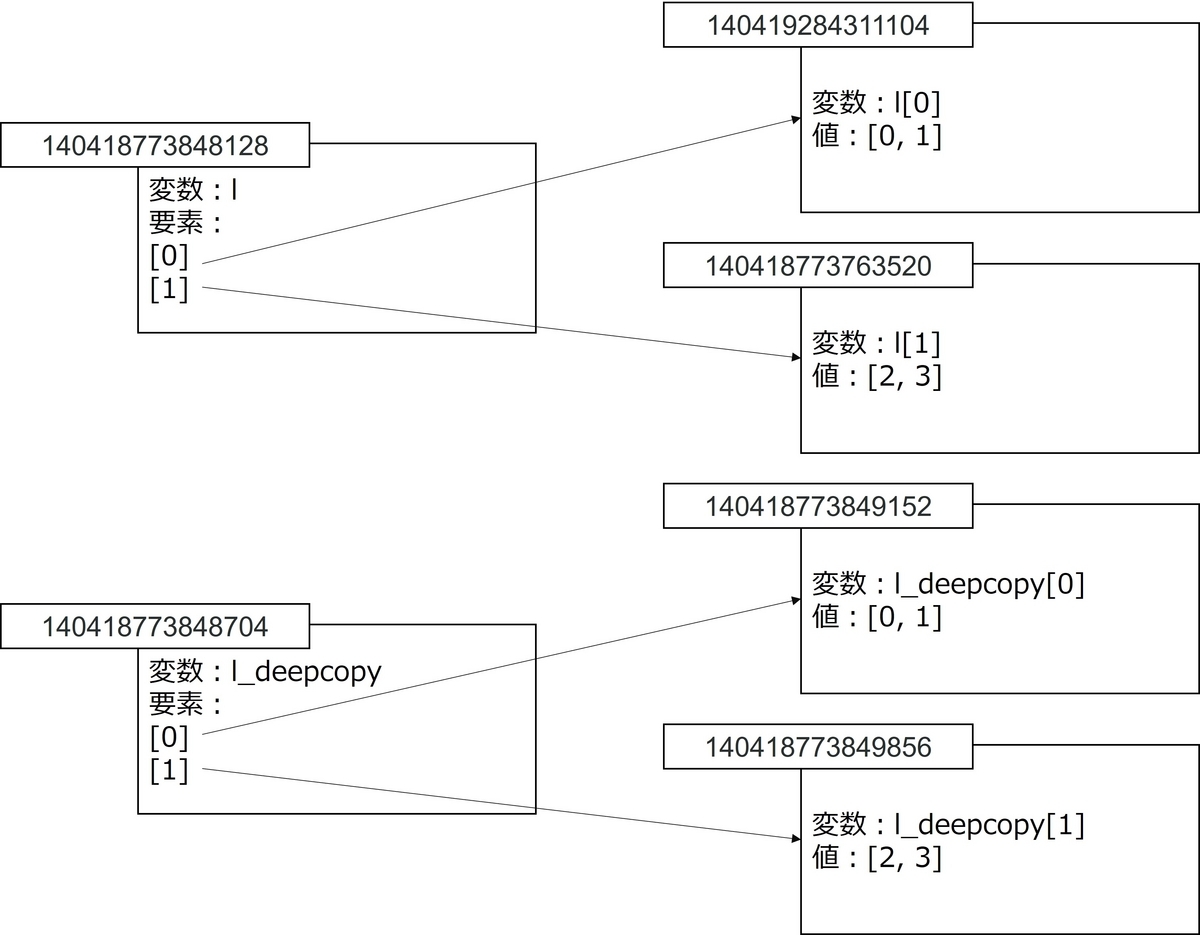
上表を見ると、l[0]とl_deepcopy[0]のオブジェクト、l[1]とl_deepcopy[1]のオブジェクトが異なることがわかります。つまり、深いコピーを行うと、新規のオブジェクトが作成され、さらにその要素についても新しいオブジェクトが作成されます。
図4:深いコピー時で作成したオブジェクト
要素の値を変更したらどうなる?
ミュータブルな要素の値を変更したとき
本節では、元の複合オブジェクトの要素を変更したときに、浅いコピーと深いコピーで作成されたオブジェクトの挙動を説明します。ただし、元の複合オブジェクトの要素はミュータブルとします。
l[0 ][0 ] = 100
print (f"l = {l}" )
print (f"l_shallowcopy = {l_shallowcopy}" )
print (f"l_deepcopy = {l_deepcopy}" )
出力結果は下記のようになりました。
変数名
値
l
[[100, 1], [2, 3]]
l_shallowcopy
[[100, 1], [2, 3]]
l_deepcopy
[[0, 1], [2, 3]]
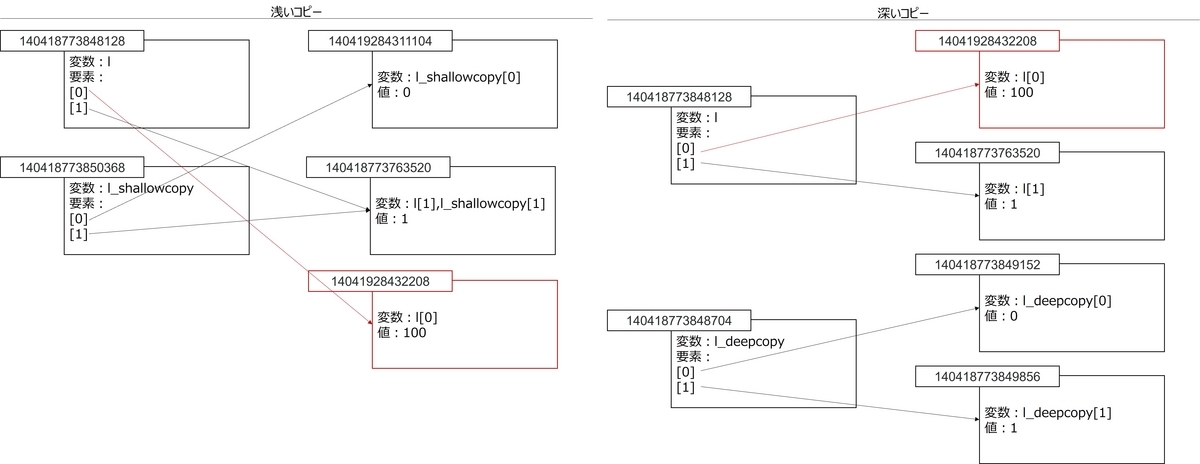
l_shallowcopyはlの変更に伴い値が変更されました。これは、l_shallowcopy[0]とl[0]のオブジェクトが一致しているためです。l_deepcopyはlの変更に伴った値の変更がありません。これは、l_deepcopy[0]とl[0]のオブジェクトが一致していないためです。図5はこのことを説明した図です。
図5:ミュータブルなオブジェクトを変更したときの挙動
なお、上記のような挙動となるのは複合オブジェクトの要素がミュータブルなときであることに注意してください。l[0]のオブジェクトはリストなので、ミュータブルです。したがって、l[0][0]の値が変更されても、l[0]のオブジェクト自体は変わらず、l_shallowcopy[0]の値も変更されました。
イミュータブルな要素の値を変更したとき
最後に元の複合オブジェクトの要素を変更したときに、浅いコピーと深いコピーで作成されたオブジェクトの挙動を説明します。ただし、元の複合オブジェクトの要素はイミュータブルとします。
import copy
l = [0 , 1 ]
l_shallowcopy = l.copy()
l_deepcopy = copy.deepcopy(l)
l[0 ] = 100
print (f"l = {l}" )
print (f"l_shallowcopy = {l_shallowcopy}" )
print (f"l_deepcopy = {l_deepcopy}" )
出力結果は下記のようになりました。
変数名
値
l
[100, 1]
l_shallowcopy
[0, 1]
l_deepcopy
[0, 1]
上表を見ると、l[0]の変更に伴ったl_shallowcopy[0]の変更がありません。l = [[0, 1], [2, 3]]のときは、l_shallowcopyの値が変更されたのに、今回は値が変更されていません。なぜでしょうか?l[0]がイミュータブルなオブジェクトだからです。イミュータブルなオブジェクトの場合、値を変更すると新しいオブジェクトが作成されます。したがって、l[0]は新しいオブジェクトになるが、l_shallowcopy[0]は元のオブジェクトを参照しているため、値が異なるという結果になります。図6はこのことを説明した図です。
図6:イミュータブルなオブジェクトを変更したときの挙動
まとめ
本記事では、Python における浅いコピーと深いコピーについて説明しました。浅いコピーと深いコピーの特徴は次のようにまとめられます。
浅いコピー
浅いコピーをすると、新しい複合オブジェクトが作成される。しかし、その要素は元のオブジェクトと同じ。
元の複合オブジェクトの要素を変更すると
要素がミュータブルな場合、浅いコピーによって作成された複合オブジェクトの要素も変更される。
要素がイミュータブルな場合、浅いコピーによって作成された複合オブジェクトの要素は変更されない。
深いコピー
深いコピーをすると、新しい複合オブジェクトが作成される。また、その要素も新しいオブジェクトになる。
元の複合オブジェクトの要素を変更すると
要素がミュータブル、イミュータブルに関係なく、深いコピーによって作成された複合オブジェクトの要素は変更されない。
")

番目の説明変数:
を
個のユニットを並べ、ロジスティック関数による変換を行い予測とします(図2)。

個のユニットを並べ、ソフトマックス関数による変換を行い予測とします(図3)。