サマリ
前回記事(下記)では、AdaBoostをスクラッチ実装したスクリプトを提示しました。本記事では前回記事で作成したスクリプトを、再利用性や可読性が高まるようにリファクタリングした結果を提示します。
aisinkakura-datascientist.hatenablog.com
具体的には下記の3種類の変更をスクリプトに施しました。
- メソッドが単一責任になるようにした。これにより、アルゴリズムに変更が生じた際に、どのメソッドを変更すれば良いのか分かりやすくなる(再利用性が高まる)。
- 変数名やメソッド名を分かりやすくした。これにより、コメントをつけずともメソッドや変数が何を指し示すものかわかるようにした(可読性が高まる)。
- コメントの付け方を見直した。特に不要なコメントの削除と必要なコメントの追加を行った(可読性が高まる)。
リファクタリングの実施
import math import numpy as np class AdaboostHandmade: ''' n_estimetors:学習する弱分類器の個数 weak_learner:弱分類器(DecisionTreeClassifier)を想定 ''' def __init__(self, n_estimators, WeakLearner, **params): self._n_estimators = n_estimators self._WeakLearner = WeakLearner self._params = params @property def n_estimators(self): return self._n_estimators @property def WeakLearner(self): return self._WeakLearner @property def params(self): return self._params def fit(self, X, y): # 弱分類器を保存するためのリスト self.weak_learner_list = [] # alpha_mを保存するためのリスト self.alpha_m_list = [] # 重み weight = [1/len(X)]*len(X) weight = np.array(weight) # 弱分類器を連続して作成する for m in range(self.n_estimators): # 弱分類器のインスタンスを作成する weak_learner = self._WeakLearner() weak_learner.set_params(**self._params) # 弱分類器の学習 weak_learner.fit(X, y, sample_weight=weight) self.weak_learner_list.append(weak_learner) # err_mを計算する y_pred = weak_learner.predict(X) err_rate = (y != y_pred).astype("float") err_m_numerator = np.dot(weight, err_rate) err_m_denominator = np.sum(weight) err_m = err_m_numerator/err_m_denominator # alpha_mを計算する self.alpha_m = math.log((1-err_m)/err_m) self.alpha_m_list.append(self.alpha_m) # 重みを更新する weight = weight*np.array([math.exp(tmp) for tmp in self.alpha_m*err_rate]) ## 重みを更新する weight = weight/np.sum(weight) return def predict(self, X): pred_y_rate_list = np.array([weak_learner.predict(X) for weak_learner in self.weak_learner_list]) pred_y_rate_list_decode = 2*pred_y_rate_list-1 pred_y_rate_list_encode = np.apply_along_axis(lambda gx:np.dot(self.alpha_m_list, gx) , axis=0, arr=pred_y_rate_list_decode) pred_y_list_decode = (pred_y_rate_list_encode>=0).astype("float") return pred_y_list_decode
このスクリプトには、以下の問題があります。
- メソッドが単一責任になっていない
- 例えば、
fitメソッドは様々な指標の更新や、更新に必要な数値の計算を一手に引き受けています。そのため、各指標がどのように関連しているのか分かりにくいです。指標の更新式に変更が生じた際に、どこを変更すべきなのかわかりにくいです。
- 例えば、
- 変数名が適切ではない
predictメソッド内でpred_y_rate_listなどの変数がありますが、これは実態を表せていません(rateの名前がついているが、実際は0, 1の二値が要素として入っている)。変数名が実態を表していないと可読性が下がるので、変数名の修正が必要です。
- コメントが適切ではない
- コードを見ればすぐにわかるコメントが付いていたり、分かりにくいコードにコメントがついていません。そのため、コメントの削除や追加が必要です。
メソッドの単一責任化
ここでは、メソッドを単一責任にします。基本的にはアルゴリズムのステップとメソッドが1対1になるようにします。ただし、は、重み付き誤分類率の計算と重み更新の両方で使うので、一つのメソッドとして切り出しました。表1は、アルゴリズムとメソッドの対応をまとめた結果です。
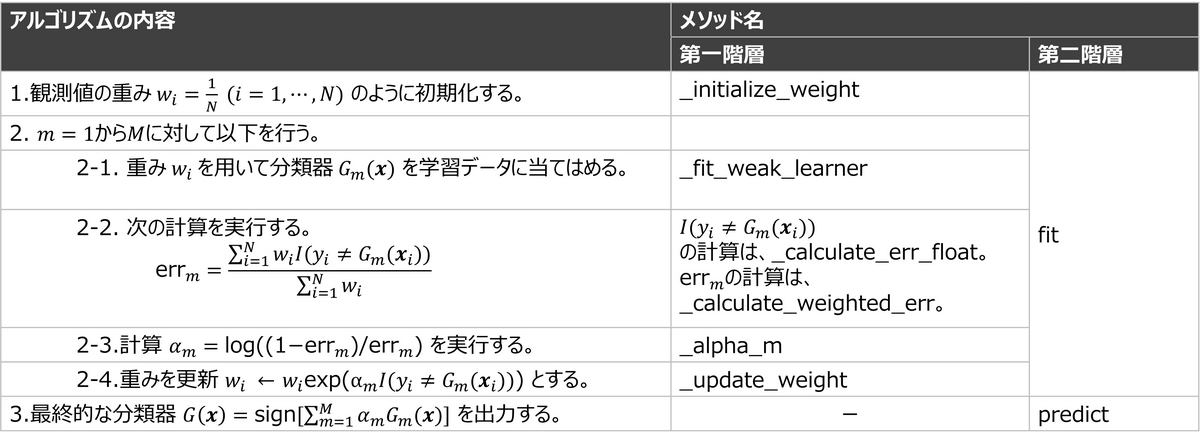
メソッドを単一責任にして、リファクタリングしたスクリプトは下記です。
import math import numpy as np class AdaboostHandmade: ''' n_estimetors:学習する弱分類器の個数 weak_learner:弱分類器(DecisionTreeClassifier)を想定 params:弱分類器のパラメータ ''' def __init__(self, n_estimators, WeakLearner, **params): self._n_estimators = n_estimators self._WeakLearner = WeakLearner self._params = params @property def n_estimators(self): return self._n_estimators @property def WeakLearner(self): return self._WeakLearner @property def params(self): return self._params def fit(self, X, y): # 弱分類器を保存するためのリスト self.weak_learner_list = [] # alpha_mを保存するためのリスト self.alpha_m_list = [] # 重みの初期化 weight = self._initialize_weight(X) # 弱分類器を連続して作成する for m in range(self.n_estimators): # 重みw_iを用いて分類器G_m(x)を学習データに当てはめる weak_learner = self._fit_weak_learner( X=X, y=y, sample_weight=weight, WeakLearner=self.WeakLearner, **self.params) # 重み付き誤分類率の計算 ## 予測値を計算(err_rateは重みの更新の際にも用いる) err_float = self._calculate_err_float(X, y, weak_learner) ## 重み付き誤分類率の計算 err_m = self._calculate_weighted_err(X, weight, err_float) # alpha_mを計算する alpha_m = self._alpha_m(err_m) # 重みを更新する weight = self._update_weight(weight, alpha_m, err_float) # self.listに追加すべきものを追加 self.weak_learner_list.append(weak_learner) self.alpha_m_list.append(alpha_m) # 何も返さない return def predict(self, X): # 弱分類器の列から予測の列を出力 pred_y_rate_list = self._predict_by_weak_lerner_list(X, self.weak_learner_list) # 予測値を0,1から-1,1に変換する pred_y_rate_list_decode = self._decode_pred(pred_y_rate_list) # 弱分類器による合議を行う pred_y_rate_list_encode = self._ensemble_by_weak_learner_list(self.alpha_m_list, pred_y_rate_list_decode) # 合議結果にsign関数をかます pred_y_list_decode = self._sign(pred_y_rate_list_encode) return pred_y_list_decode # fit内で用いるメソッド ## 最小単位のメソッド ### 重みを初期化するメソッド def _initialize_weight(self, X): # 長さXのリストを作成する weight = [1/len(X)]*len(X) # リストをndarrayに変換する weight = np.array(weight) return weight ### 弱分類器を初期化するメソッド def _initialize_weak_learner(self, WeakLearner, **params): weak_learner = WeakLearner(**params) return weak_learner ### 予測値の計算 def _calculate_err_float(self, X, y, weak_learner): # 予測値をbooleanで計算 y_pred = weak_learner.predict(X) # 異なるなら1、一致するなら0のfloatに変換 err_float = (y != y_pred).astype("float") return err_float ### 重み付き誤分類率の計算 def _calculate_weighted_err(self, X, weight, err_float): # 重み付き誤分類率を計算 err_m = np.dot(weight, err_float)/np.sum(weight) return err_m ### alpha_mの計算 def _alpha_m(self, err_m): return math.log((1-err_m)/err_m) ### ここから修正 # 重みの更新 def _update_weight(self, weight, alpha_m, err_float): # 重みを更新する weight = weight*np.array([math.exp(tmp) for tmp in self.alpha_m*err_float]) # 重みを正則化する weight = weight/np.sum(weight) return weight ## アルゴリズムの各ステップのレベルにまとめたメソッド ### 重みw_iを用いて分類器G_m(x)を学習データに当てはめる def _fit_weak_learner(self, X, y, sample_weight, WeakLearner, **params): # 弱分類器のインスタンスの初期化 weak_learner = self._initialize_weak_learner(WeakLearner, **params) # 弱分類器の学習 weak_learner.fit(X, y, sample_weight=sample_weight) return weak_learner # predict内で用いるメソッド ## 弱分類器の列から予測の列を出力するメソッド def _predict_by_weak_lerner_list(self, X, weak_learner_list): return np.array([weak_learner.predict(X) for weak_learner in weak_learner_list]) ## 予測値を0, 1から-1, 1に変換するメソッド def _decode_pred(self, pred_y_rate_list): return 2*pred_y_rate_list-1 ## 弱分類器による合議を行うメソッド def _ensemble_by_weak_learner_list(self, alpha_m_list, pred_y_rate_list_decode): # signに入れる値の計算 return np.apply_along_axis(lambda gx:np.dot(alpha_m_list, gx) , axis=0, arr=pred_y_rate_list_decode) # sign関数(np.signだと0も返されてしまうので、自分で実装する) def _sign(self, pred_y_rate_list_encode): return (pred_y_rate_list_encode>=0).astype("float")
変数名の修正
predictメソッド内の変数の実態と変数名が合っていないので修正しました。具体的には、xxx _ 取りうる値 _ 型名という変数名に修正しました。修正後のスクリプトは下記です(predictメソッドのみ記載)。
def predict(self, X): ''' 引数 - X:特徴量(pd.DataFrmae) 返り値: - 予測値(ndarray) ''' # 弱分類器の列から予測の列を出力.値は0, 1 pred_0_1_ndarray = self._predict_by_weak_lerner_list(X, self.weak_learner_list) # 予測値を0,1から-1,1に変換する pred_minus1_1_ndarray = self._decode_pred(pred_0_1_ndarray) # 弱分類器による合議を行う ensembled_pred_minus1_1_list = self._ensemble_by_weak_learner_list(self.alpha_m_list, pred_minus1_1_ndarray) # 合議結果にsign関数をかます ensembled_pred_minus0_1_ndarray = self._sign(ensembled_pred_minus1_1_list) return ensembled_pred_minus0_1_ndarray
コメントを適切につける
見た瞬間に分かるコードにもコメントをつけたり、逆に注意すべき点にコメントをつけていなかったりしました。コメントを修正したfitメソッドを載せます。
def fit(self, X, y): ''' 引数 - X:特徴量(pd.DataFrmae) - y:目的変数(pd.DataFrame) 返り値:なし(ただし、self.weak_learner_listとself.alpha_m_listを更新する) ''' # 初期化 self.weak_learner_list = [] self.alpha_m_list = [] weight = self._initialize_weight(X) # 弱分類器を連続して作成する for _ in range(self.num_weak_leaner_list): # 重みw_iを用いて分類器G_m(x)を学習データに当てはめる weak_learner = self._fit_weak_learner( X=X, y=y, sample_weight=weight, WeakLearner=self.WeakLearner, **self.weak_learners_params) # 指標の更新に用いる数値の計算 ## err_floatは異なるなら1、一致するなら0のndarray ## err_floatはerr_m, weightの計算に用いる err_float = self._calculate_err_float(X, y, weak_learner) err_m = self._calculate_weighted_err(X, weight, err_float) # 各指標の更新 alpha_m = self._calculate_alpha_m(err_m) weight = self._update_weight(weight, alpha_m, err_float) # リストへの追加 self.weak_learner_list.append(weak_learner) self.alpha_m_list.append(alpha_m) return
まとめ
今回は、下記の本を参考にしてリファクタリングを行いました。リファクタリングを実践してみて感じたことは、可読性・再利用性を高めることは「奥が深い」ということでした。今後、可読性・再利用性が高いコードを書けるようになるべく鍛錬していきたいと思います。

")