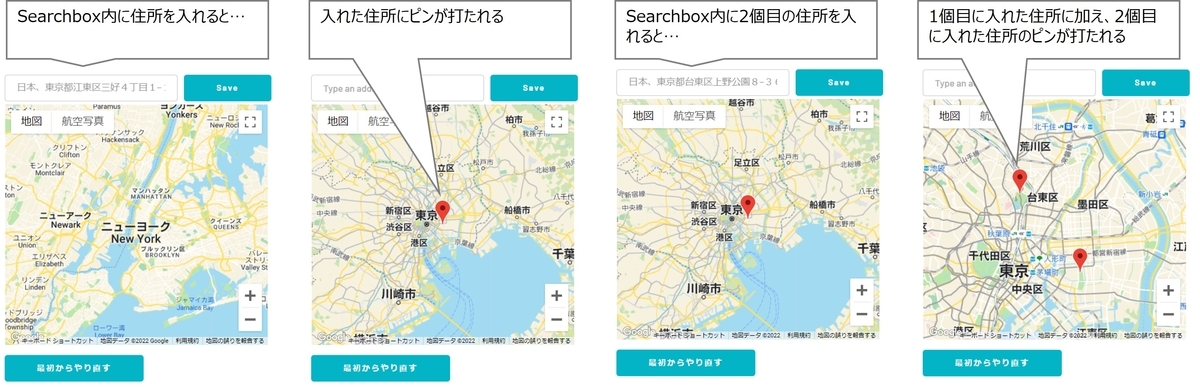
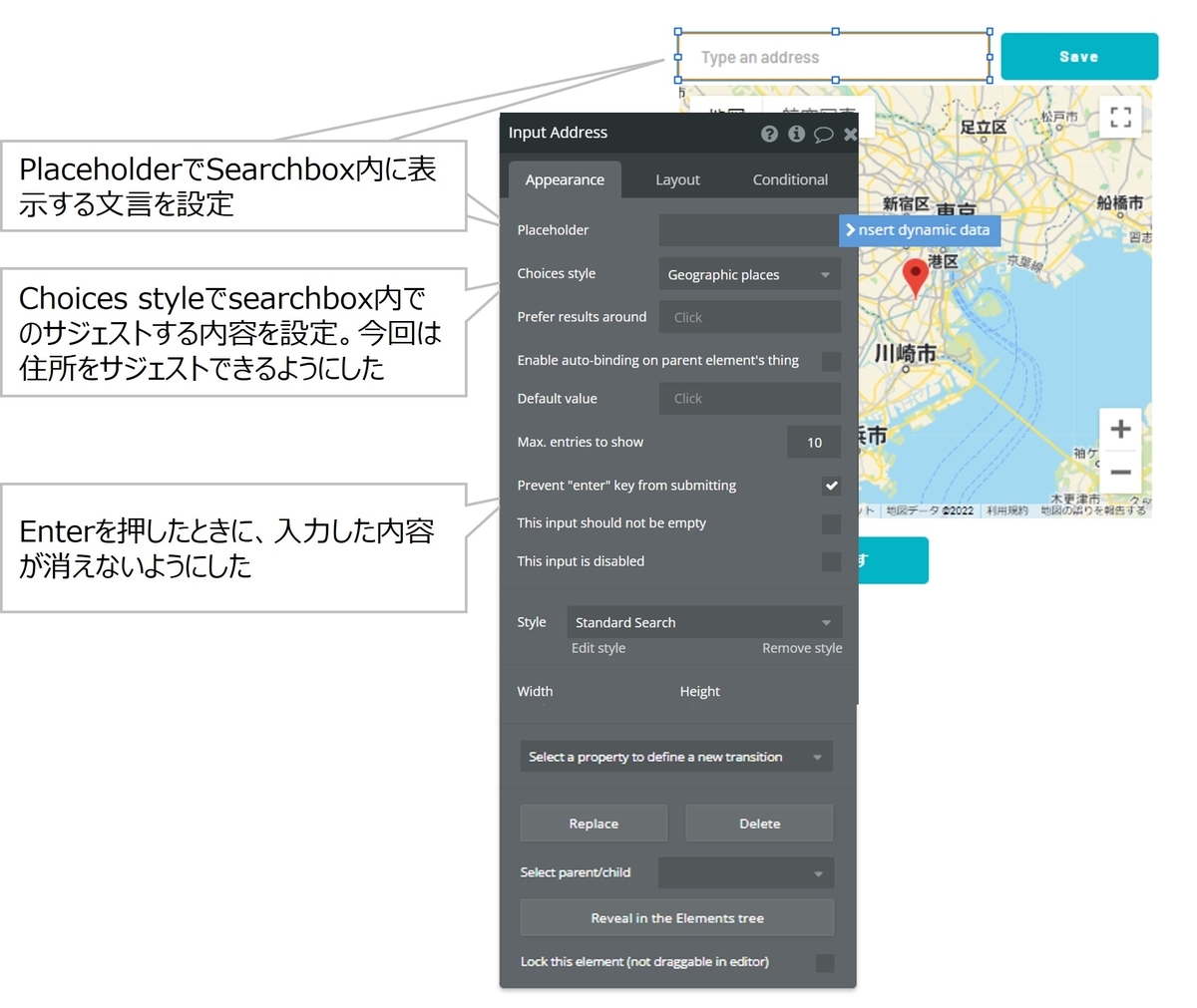
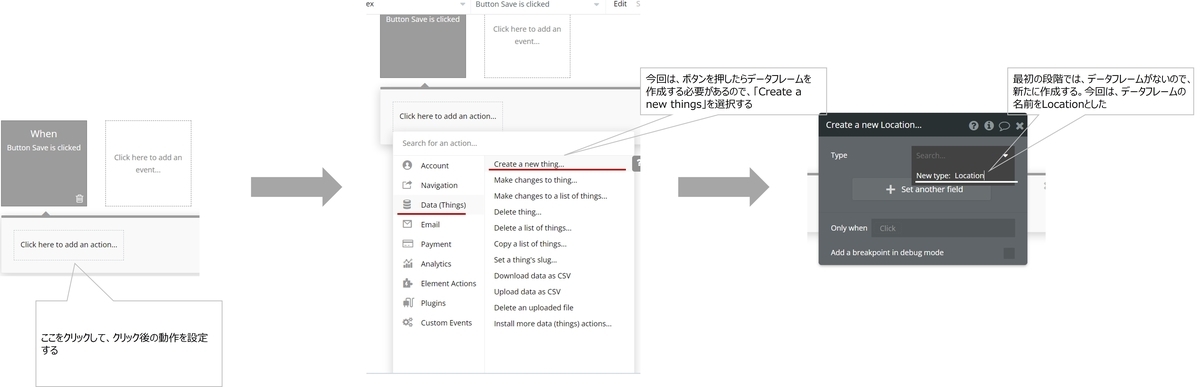
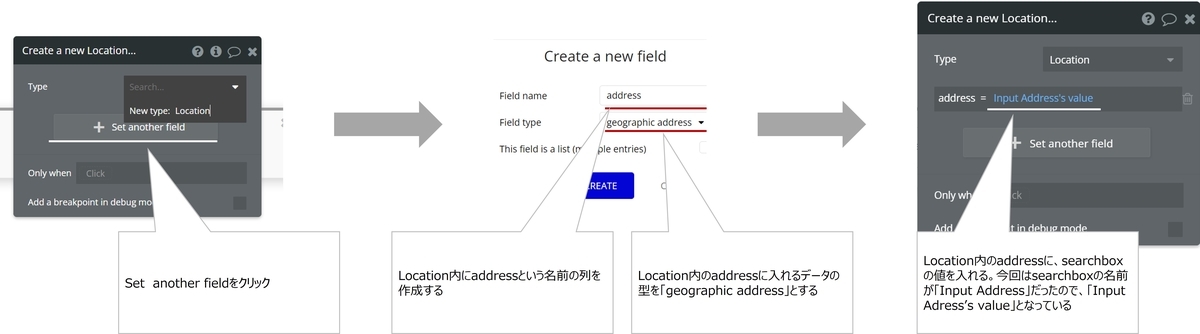
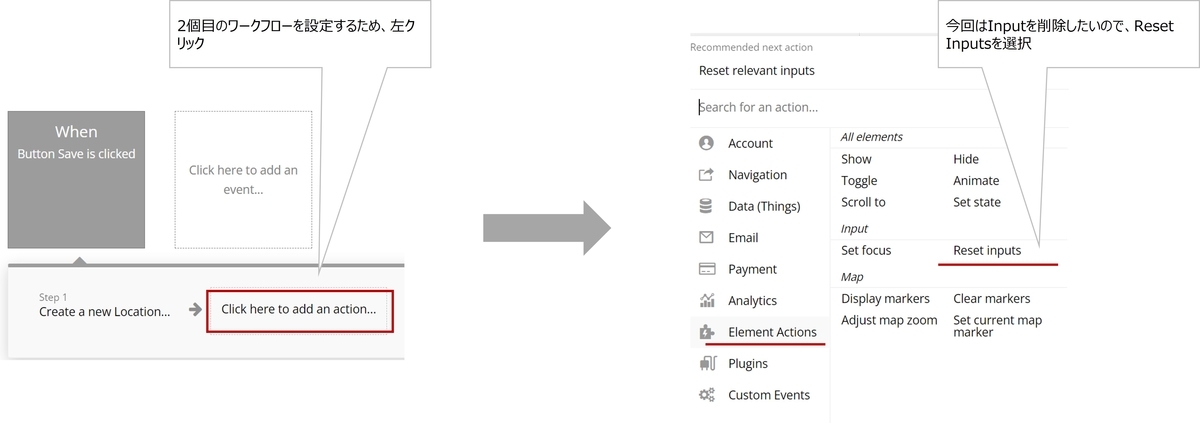
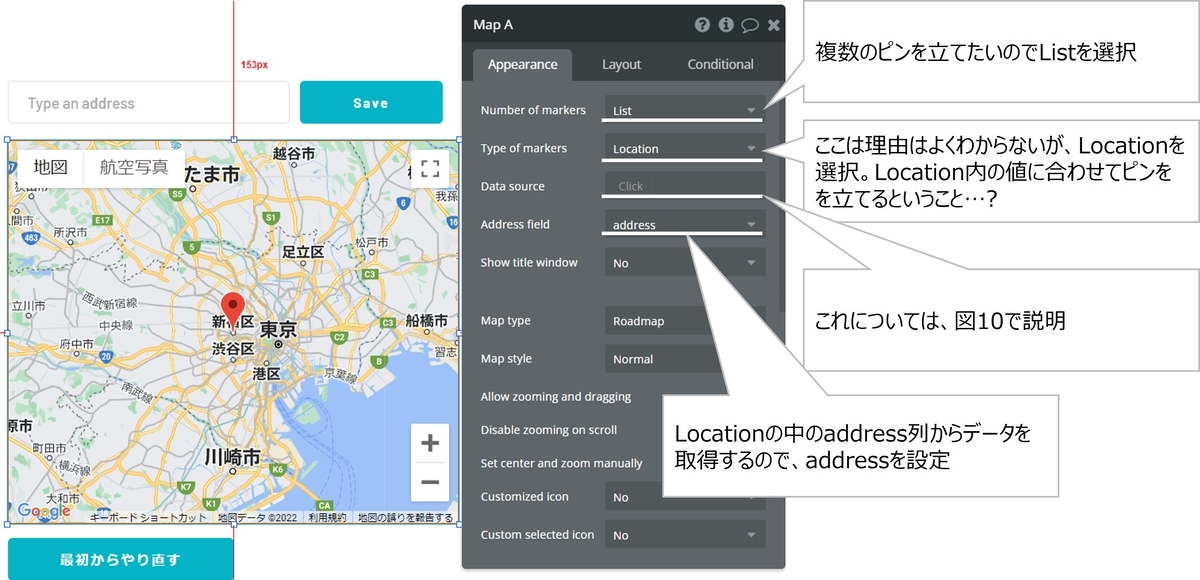
")
ヒット本でした。
マーケティング業界では、よく「顧客目線で考える」とか「顧客が求めていることを知るべき」と言われることがあります。しかし、実際の業務においては、顧客目線で考えることは困難です。その理由の一つに顧客目線で考えるためのとっかかりが見つからないということがあります。
そんな状況の中で、株式会社デコムは顧客が持つ「人を動かす隠れた心理」を見つけ、マーケティングに活用しているようです。本書は、その「人を動かす隠れた心理」を見つけるためのデコム流の方法論が惜しげもなく紹介されています。
※本記事は自分が後から見直して活用できるように、論点をあまり絞らずダラダラ書いています。 一言書評を知りたい方は読書メータをご覧ください。
「人を動かす心理」を見つけなければならない理由
サービスの存在意義の一つに、消費者の不満解消があると思います。この不満に気付けるかがサービス開発に重要なのですが、顧客からアンケートなどを取っても、なかなかイノベーションを起こせるような不満に出会うことはできません。 本書では、スマートロックを例にして次のように説明されています。
大事なのは「何かお困り事はありますか?」と聞いて「カバンから鍵をいちいち取り出すのが面倒」「財布から小銭をチマチマ出すのが面倒」と答える人はいない、ということです。もともとそうした不満はあるのに、なぜか気付けないのです。
不満を解消したいのに、肝心の不満を見つけることができないということがマーケティングの難しさの一つだと思います。
本書の構成
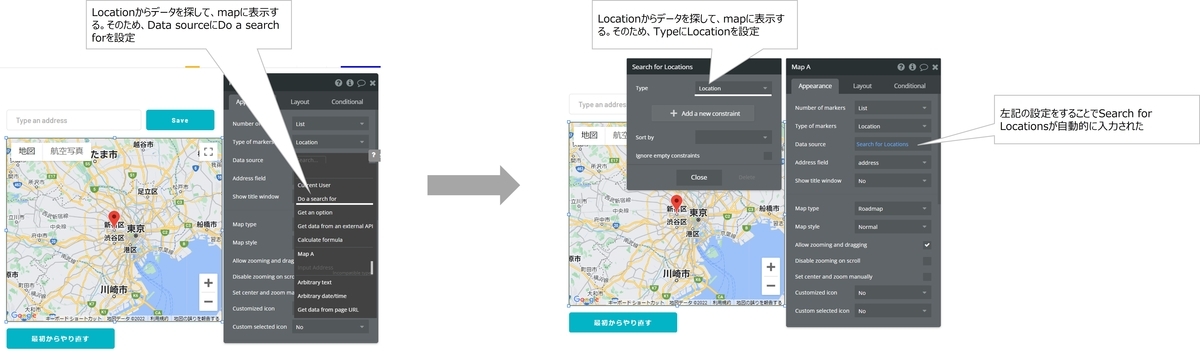
本書の構成について、図1にまとめました。「数値A-(数値B)」となっているのは、数値Aの章の数値Bの節にその内容が書いてあるという意味です。また、図中の用語(「インサイト」など)についてはこの後で説明していきます。

図1中の矢印、A→Bの意味は、「良いAが良いBを生み出す」です。つまり、良い新奇事象と良い価値年表が良いオポチュニティを生み出し、良いオポチュニティが良い価値事象を生み出し...とつながっていきます。
この後は、各用語の意味を説明していきます。
新奇事象

図2に新規事象のsumamryを記載しました。下記で補足していきます。
定義
新奇事象を収集する上でのポイントは、ユニークな行動を収集することです。本書には、顧客視点で物事を考える際には違和感を持ったポイントを抑えると良いという主張があります。その点、新奇事象は違和感の塊なので、違和感を通じて価値を発見しやすいという利点があります。
関連するフォーマット
新奇事象に関連するフォーマットを4個挙げました。
- 生活14カテゴリ
生活14カテゴリとは、図3のように人間の興味・関心を14個のカテゴリに分けたものです。人々の興味・関心はこの14カテゴリに収まるだろうというのがデコムの考え方です。 このカテゴリを使うことで、自社が提供している価値以外の価値に、価値を感じているユーザを探すことに役立ちます。ここで探した自社が提供している価値以外の価値を感じている新奇事象を収集することが、新規顧客開拓に役立ちます。

- LIV
Layer+Issue+Valueの略です。意味と例を下記にまとめました。本書ではデパートを例にしています。
| 項目 | 説明 | 例 |
|---|---|---|
| Layer | ブランドを抽象・概念化したカテゴリ | 日帰り旅行 |
| Issue | ブランドが抱える課題 | 若年層の利用が少ない |
| Value | ブランドの価値 | 自分をラグジュアリーな存在だと錯覚させる空間、人 |
これらを整理することで、例えばデパートであれば日帰り旅行が好きな若年層を新規顧客のターゲットとする発想が浮かびます。
- 事象を表すためのタイトル+事象の世界観を表す画像+事象内容+個人のデモグラ
これは収集した新奇事象を整理するためのフォーマットです。図4に例を記載します。

- 新奇事象から意味を抽出するための質問群
これが一番大切です。というのも、新奇事象から消費者が満たされていない不満や、消費者が感じる価値を見つけることで、次のオポチュニティにつなげるからです。本書では、この質問群は次のようにまとめられています。
①自社ブランド/当該カテゴリが提供していない価値領域がありそうな行動を起こしているか?
②自社ビジネスで解決できそうか?
③人間の潜在的な不満、満足、未充足が隠れているか?
この質問群に答えることによって、新奇事象から消費者が感じている不満・価値を炙りだしていきます。
例
図4に記載した新奇事象を基に、上記の質問群に答えてみます。
①自社ブランド/当該カテゴリが提供していない価値領域がありそうな行動を起こしているか?
弊社で提供しているサブスクサービスは、クーポンや書籍などのエンタメ作品を提供しています。それに対して、図4の新奇事象では「巫女装束」というモノを通じて、男性はリラックスしています。また、本物の巫女装束というのもポイントで、弊社で提供しているある意味バーチャルな経験ができるエンタメとは異なるところに価値があります。
そのため、この質問に対する答えを「本物の巫女装束を着ることでリラックスできる。巫女装束はスイッチをOFFするための道具」としようと思います。
②自社ビジネスで解決できそうか?
弊社で提供しているサブスクサービスを通じて、どうすればリラックスタイムを提供できるか考えてみます。
ポイントの一つは、本物のモノを通じてリラックスすることにあるのでコーヒーやお酒など嗜好品の通販クーポンなどが思い浮かびます。
また、エンタメサービスはもともとリラックスタイムを提供できるサービスだと思います。
そこで、自社ビジネスでは「家にコーヒーやお酒などの嗜好品を届けるサービスのクーポン券とエンタメサービスを抱き合わせてユーザに提案する」などが考えられます。
③人間の潜在的な不満、満足、未充足が隠れているか?
今回の場合は、介護という仕事からくるストレスが不満にあたると思います。
おまけ
ここでは、新奇事象を考える上での注意点を2点説明します。
注意点1:既存価値年表の枠外は全て受け入れる
既存価値年表については、この後詳しく説明しますが、要するに過去に自社ブランド、もしくは自社ブランドが所属するカテゴリが提供してきた価値を年表にしたものです。この既存価値年表に載っている価値以外の価値は全て新しい価値です。新奇事象から価値を抽出する段階では、この新しい価値を全て受け入れて、この後の作業で取捨選択していけば良いと本書に書いてあります。注意点2:エンジェルインサイトとデビルインサイトの両面を理解する
人間の欲望には、良い面と悪い面と両方あります。本書では、欲望の良い面と悪い面について以下のように指摘しています。
優れたアイデアやクリエイティブは、エンジェルインサイトとデビルインサイトの双方を押さえていると言えるでしょう。(中略) エンジェルインサイトとデビルインサイトのどちらか片方のみで成り立つアイデアは、成功する可能性が極めて低いと考えています。
デコムはエンジェルインサイトとデビルインサイトをまとめた欲望マンダラを作成しているようです。

既存価値年表

図6に既存価値年表のsumamryを記載しました。下記で補足していきます。
定義
既存価値年表を作成する目的は、サービスを開発するメンバー間で既に提供してきた価値を共有することです。これにより、新奇事象で抽出した価値を既に提供してしまったものなのか、まだ未提供なのかを判別することができます。
関連フォーマット・例
縦軸にPEST、データ、価値定義、4P、3CのうちのCustomerを並べ、横軸に年代を並べます。年代は10年ごとくらいがちょうどよいとのことです。*1。
図7は、本書記載の居酒屋チェーンの既存価値年表です。

おまけ
「事象→価値」のルールで矢印が書かれている
既存価値年表中では、発生した事象がどのような価値を生み出したかを矢印で表現します。この矢印を書いておくことで、新奇事象がどのような価値を生み出すかの参考になるのではないかと私は考えています。2~3年は続いた価値を記載する
あまりにも短い価値は「一発屋」で定着しなかったとして既存価値年表に載せる必要はないとのことでした。あくまでトレンドを捉えることが重要とのことです。CMを参考にすると良い
過去のCMには、そのサービスが提供・訴求しようとした価値が詰め込まれています。なので、Youtube等に載っているCMを見て、既存価値年表作成に役立てると良いそうです。
オポチュニティ

定義
オポチュニティの定義のポイントは、「十分に充たされていない」「新しい価値」「仮説」の3つだと私は考えています。
十分に充たされていないから、新しくサービスを提供する、新しい価値としてサービスを訴求することに意味があるということが考えられます。
また、既存の価値ではなく新しい価値だからこそ(二番煎じでないからこそ)、集客力があると考えられます。
最後に仮説についてですが、オポチュニティはあくまで「この価値は十分に充たされてないだろう」と帰納的に導き出された価値です。なので、テストマーケティングなどを実施し、正しいかどうかを検証する必要があります。
関連するフォーマット・例
デコムが開発したフォーマットを図9に載せます。記載内容は海外旅行に関するものです。

フォーマット内の「気づき」は新奇事象に触れて得られた気づきです。また、この後作られるインサイトから生み出すアイデアについても、オポチュニティを整理しだしたくらいから考え始めるべきなのだと思います。それがこのフォーマットに「新路線の例えばアイデア」が載っている理由だと考えています。
価値事象
定義
ここまでも少し触れてきましたが、顧客の不満を炙りだすことがインサイト発見には必要です。本書では、不満を炙りだすためのテクニックとして、価値に照らし合わせて顧客調査することが提案されています。
例えば、缶コーヒーに「部下とコミュニケーションをとるきっかけを作ってくれる」という価値を見つけたとします。このとき、顧客には「部下とコミュニケーションを取るために缶コーヒーを購入するあなたにとって、缶コーヒーの不満は?」と質問するのです。そうすることで、具体的な不満、例えば「5、6人で休憩したいときには向いていない」などを炙りだせるとのことです。私としては、実際にはこんなにうまくいくことは少ないかもしれませんが、納得感はあるなと思いました。
以上のような顧客調査をするためには、オポチュニティ作成の際に手に入れた「新しい価値」を感じているユーザを集めてきて不満を聞く必要があります。この、新しい価値を感じている顧客の行動を「価値事象」と本書では定義されています。
関連するフォーマット・例
シーン・ドライバー・エモーション・バックグラウンドの4点をセットにして価値事象を整理します。これにより、客観的事実であるシーン・ドライバー・バックグラウンドと、主観的事実であるエモーションをセットにして整理することができます。
インサイトが「隠れた心理」である以上、主観的事実であるエモーションが一番重要なのではないかと私は考えています。
図10に本書記載の例を載せておきます。

おまけ
価値事象も顧客調査等で集めてくる事象です。これについて、新奇事象のための顧客調査と混乱してしまったのですが、目的が異なります。 新奇事象のための顧客調査の目的は、ユニークな行動を集めることで、その人しか感じていない価値を探すことです。一方で、価値事象は新奇事象から抽出した価値を感じている人を集めてきて、サービスへの不満を炙りだすことにあります。関係性を図11にまとめました。

インサイト

定義
インサイトとは「人を動かす隠れた心理」のことです。本書では、インサイトが次の様に説明されています。
この書籍ではインサイトを「人を動かす隠れた心理」と定義します。
ポイントが2つあります。1つ目は「隠れている」点、2つ目は「動かす」点です。
隠れていなければ、つまり露出していれば、それは単なる「ニーズ」に過ぎません。(中略)隠れているからこそ、「何かお困りごとはありますか?」と聞いても分からないのです。
また、人が動かなければ、残念ながらビジネスには使えません。最終的には消費者に商品・サービスを購入してもらわなければならないので、人が動かない心理を発見しても仕方がないのです。
関連するフォーマット・例
価値事象の分析結果を基に不満を炙りだします。そのためのフォーマットが図13です。

おまけ
インサイトは「隠れた心理」である以上、エモーション(情緒)までしっかり考えきることが重要です。むしろ、情緒までしっかり考えきれていないと意味がないと言えます。
アイデア

定義
ここまで整理してきたインサイトによって、消費者の不満を掴むことはできました。なので、今度はその不満を解消するためにサービスを開発しなければなりません。ここでは、一般的なアイデアという言葉の意味を狭めて「消費者の不満を解消するための提案」としています。
関連するフォーマット・例
インサイトを一言でまとめたものと、それに対する提案(=バリュープロポジション)をセットにしてアイデアを出していきます。

おまけ
『アイデアのつくりかた』を読めば誰もが簡単にアイデアを大量生産できるかと問われれば、私は首をかしげます。万人ではないよなぁ......という感想を抱いているからです。どうすれば閃くのか、なぜ閃くのかが上手く説明できていません。「ある日突然閃く」というくだりが、どうしても個人の感覚や感性、偶然に依存しているように思えるのです。
つまり、『アイデアのつくりかた』を読んだところで、アイデアを生み出すことは一部の天才にしかできないというわけです。しかし、インサイトが手に入っていればアイデアを生み出すことは大分難易度が下がります。
最後に
本書は「顧客視点で考える」方法について述べた本です。本書を実践することで、マーケティング力の向上が見込めます。一方で、自分が所属している会社の場合そのまま本書の内容を活かすことは難しいぞという感覚があります。 今思いつく範囲でその理由を考えてみると、主に3点あります。
- 既に引いてある分析スケジュールや分析内容と合わない
- 顧客調査できない
- イノベーションを起こそうという気がなく、小さな改善しかできない
これらの課題は一朝一夕に解決できるものではありません。なので、明日から私が取り組むべきことは、これらの課題と共存させる方法を考えることです。 本書で学んだことが業務に活かせるよう頑張っていきたいと思います。
*1:PESTとは、Political(政治的)、Economic(経済的)、Social(社会的)、Technological(技術的)の頭文字です。
*2:引用中の『アイデアのつくりかた』は ja.wikipedia.org のこと