
目次
- 目次
- はじめに
- 勾配降下法のおさらい
- 入力が複数、出力は1つのニューラルネットワーク
- 入力が1つ、出力が複数のニューラルネットワーク
- 入力が複数、出力も複数のニューラルネットワーク
- コードに落とし込む
- MNISTデータセットにニューラルネットワークを適用させる
- まとめ
はじめに
前回記事に書いたように、現在ディープラーニングを勉強しています。
今回は、なっとく!ディープラーニングの第5章について解説していきたいと思います。
なお、第5章は次の流れで説明が進んでいきます。本記事もその流れに合わせています。
- 入力が複数、出力が1つのニューラルネットワークの更新式を導出する
- 入力が1つ、出力が複数のニューラルネットワークの更新式を導出する
- 入力が複数、出力も複数のニューラルネットワークの更新式を導出する
- MNISTデータセットにニューラルネットワークを適用させる
1, 2を理解すれば3の理解は簡単です。一方で4を理解することは難しく、きっちりと理解したいのであれば、しっかりと本書を読み込むべきだと思います。
勾配降下法のおさらい
勾配降下法とは、ディープラーニングにおいてパラメータを推定する手法の一つです。パラメータを下記の更新式にしたがって更新します。
ただし、は更新後のパラメータ、
は更新前のパラメータ、
は学習率、
は損失関数です。
によって更新の方向が、
によって更新の大きさが決まります。
前回記事では、入力が一つ、出力も一つ、層も一つのニューラルネットワークについて、具体的な更新式を説明しました。本記事では、入力や出力が複数になった場合のニューラルネットワークについて、勾配降下法の更新式を導出します。
入力が複数、出力は1つのニューラルネットワーク
図1のようなニューラルネットワークにおける勾配降下法の更新式を具体的に導出します。

図1のニューラルネットワークの形から、予測値は、
となります。したがって、損失関数は、
となります。したがって、勾配は、
となります。したがって、更新式は
となります。
入力が1つ、出力が複数のニューラルネットワーク
図2のようなニューラルネットワークにおける勾配降下法の更新式を具体的に導出します。

図2のニューラルネットワークの形から、予測値は、
となります。また、この場合損失関数が出力ごとに存在するため、損失関数は、
となります。したがって、勾配は、
となります。したがって、更新式は
となります。
入力が複数、出力も複数のニューラルネットワーク
図3のようなニューラルネットワークにおける勾配降下法の更新式を具体的に導出します。

考え方はシンプルで、図3のニューラルネットワークを二つに分解します(図4)。

図4のニューラルネットワークのうち、A、Bの部分はそれぞれ入力が複数、出力が一つのニューラルネットワークと同じ形をしています。したがって、更新式の導出は上で説明した考え方を使えば良いです。
上で説明した考え方を使うと、Aの部分の更新式は
となります。同様にBの更新式は、
です。これらの式を行列の形でまとめると(つまり、Aの部分を1列目、Bの部分を2列目にする)
となります。
コードに落とし込む
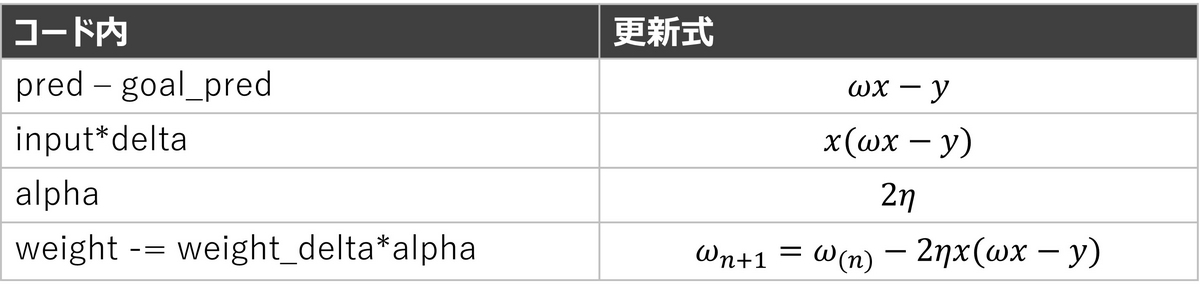
最後の更新式をJuliaで書くと以下のようになります。
using LinearAlgebra # 特徴量 toes = [8.5, 9.5, 9.9, 9.0] wlrec = [0.65, 0.8, 0.8, 0.9] nfans = [1.2, 1.3, 0.5, 1.0] # 目的変数 hurt = [0.1, 0.0, 0.0, 0.1] win = [1, 1, 0, 1] sad = [0.1, 0.0, 0.1, 0.2] # ニューラルネットワークの入力 input = [toes[1], wlrec[1], nfans[1]] # ニューラルネットワークの出力 truth = [hurt[1], win[1], sad[1]] # 重みの初期値 weights = [0.1 0.1 -0.3; 0.1 0.2 0.0; 0.0 1.3 0.1] # 学習率 alpha = 0.005 # 100回だけ更新 for i = 1:100 ## pred_vecの計算 pred_vec = weights*input ## delta_vecの計算 delta_vec = pred_vec-truth ## weights_delta_matrixの計算 weights_delta_matrix = zeros(size(input)[1], size(delta_vec)[1]) for i = 1:size(input)[1] for j = 1:size(delta_vec)[1] setindex!(weights_delta_matrix, input[i]*delta_vec[j], i, j) end end ## 更新 weights -= alpha*weights_delta_matrix ## Errorの計算 pred_vec = weights*input for delta in (pred_vec-truth) println(delta^2) end println("---") end
MNISTデータセットにニューラルネットワークを適用させる
本書の5.7節ではMNISTデータセットに対して、ニューラルネットワークを構築するトピックが出ています。本節では、理論の解説がなされているだけでコードが載っていなかったので、自分でJuliaで書いてみました。
ただし、ここまでの流れに沿ってデータが一つしかない場合のニューラルネットワークを構築しています。したがって、本書と結果が異なることはご了承ください。また、問題設定はここには記載しません。詳しくは本書を読んでいただければと思います。
パッケージの導入
まずは、必要なパッケージをインストールします。
import Pkg # 必要なパッケージのinstall Pkg.add("MLDatasets") Pkg.add("Flux")
データセットの入手
次にデータセットを入手します。今回はデータセットを一つしか使わない、かつ精度検証も行わないので学習用データだけ読み込みます。
using MLDatasets x_train, y_train = MLDatasets.MNIST.traindata(Float32)
データの前処理
データを今回作ったニューラルネットワークのコードに流し込める形に変換します。
using Flux using Flux.Data: DataLoader using Flux: onehotbatch, onecold x_train = Flux.flatten(x_train) y_train = onehotbatch(y_train, 0:9)
ニューラルネットワークの学習
最後にニューラルネットワークを学習させます。
# ニューラルネットワークの入力 input = x_train[:, 1] # ニューラルネットワークの出力 truth = y_train[:, 1] # 重みの初期値 weights = zeros(size(y_train)[1], size(x_train)[1], ) # 学習率 alpha = 0.005 # 10回だけ更新 for i = 1:100 ## pred_vecの計算 pred_vec = weights*input ## delta_vecの計算 delta_vec = pred_vec-truth ## weights_delta_matrixの計算 weights_delta_matrix = zeros(size(delta_vec)[1], size(input)[1]) for i = 1:size(delta_vec)[1] for j = 1:size(input)[1] setindex!(weights_delta_matrix, delta_vec[i]*input[j], i, j) end end ## 更新 weights -= alpha*weights_delta_matrix ## Errorの計算 pred_vec = weights*input for delta in (pred_vec-truth) println(delta^2) end println("---") end
結果
最後に学習されたパラメータをヒートマップで表示しました(図5)。なんとなく、5と書かれていることが見て取れます(向きは変ですが、、、)。 これはデータセットの1個目の目的変数の値が5だったためです。
using Pkg Pkg.add("Plots") using Plots # ヒートマップで推定されたパラメータを表示する heatmap(reshape(reshape(weights, 10, 784)'[:, 6], 28, 28)) # 5の場合

まとめ
本記事では、なっとく!ディープラーニングにしたがい、下記の流れで単層のニューラルネットワークに関する理論を紹介しました。
- 入力が複数、出力が1つのニューラルネットワークの更新式を導出する
- 入力が1つ、出力が複数のニューラルネットワークの更新式を導出する
- 入力が複数、出力も複数のニューラルネットワークの更新式を導出する
- MNISTデータセットにニューラルネットワークを適用させる
また、「入力が複数、出力が複数のニューラルネットワークの更新式を導出する」と「MNISTデータセットにニューラルネットワークを適用させる」については、Juliaによるコードも付記しました。
次回はいよいよ層を複数に拡張したニューラルネットワークについて勉強していきます。非常に楽しみです。
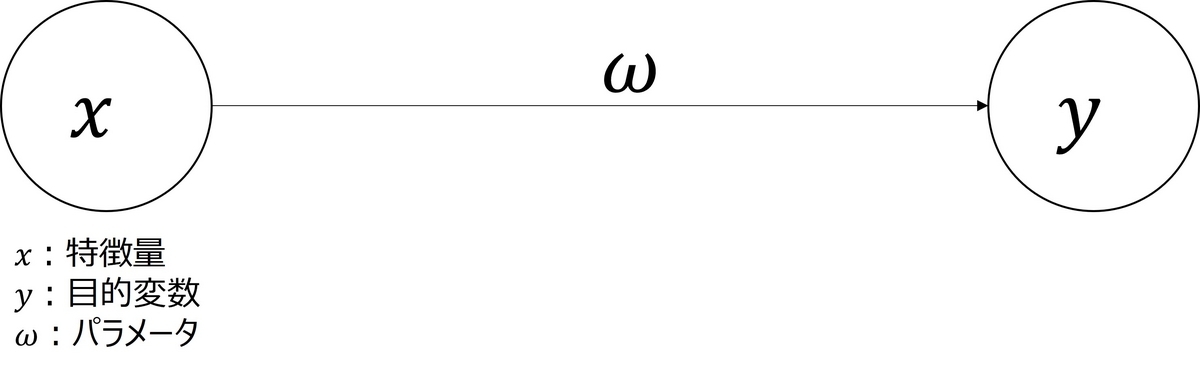

")




")
")